Datasette on Ubuntu 24.04 on Azure User Guide
Overview
Datasette is an open-source tool, created by Simon Willison, for exploring and publishing data. Point it at one or more SQLite databases and it serves an instant web UI and JSON API over them, with faceted browsing, full-text search and ad-hoc SQL queries — no schema design or front-end work required. The cloudimg image installs Datasette 0.65.2 into a Python virtualenv at /opt/datasette/venv, runs it as a dedicated datasette system user bound to loopback behind an nginx reverse proxy on TCP 80 with HTTP Basic auth, stores all SQLite databases on a dedicated Azure data disk, ships a ready-to-explore sample database, and generates a unique web password on the first boot of every VM. Backed by 24/7 cloudimg support.
What is included:
- Datasette 0.65.2 in a virtualenv at
/opt/datasette/venv, plus thedatasette-vegacharting plugin - The Datasette web UI and JSON API, fronted by nginx on
:80 - nginx HTTP Basic auth (Datasette has no built-in authentication) with a per-VM password in a root-only file
- A dedicated Azure data disk at
/var/lib/datasetteholding all SQLite databases — separate from the OS disk and re-provisioned with every VM - A bundled
demo.dbsample database (countries, cities and a sensor time series) so the UI shows real data immediately datasette.service+nginx.serviceas systemd units, enabled and active- 24/7 cloudimg support
Prerequisites
An active Azure subscription, an SSH key pair, and a VNet + subnet in the target region. Standard_B2ms (2 vCPU / 8 GiB RAM) is a good starting point; scale up for larger databases and more concurrent users. NSG inbound: allow 22/tcp from your management network and 80/tcp for the web UI and API (front with TLS for public exposure — see Enabling HTTPS).
Step 1 — Deploy from the Azure Marketplace
Sign in to the Azure Portal, choose Create a resource, search the Marketplace for Datasette by cloudimg, and select Create. On Basics pick your subscription, resource group, region and size; under Administrator account choose SSH public key and paste your key; under Inbound port rules allow SSH (22) and HTTP (80). Review the dedicated data disk on the Disks tab, then Review + create → Create.
Step 2 — Deploy from the Azure CLI
az vm create \
--resource-group <your-rg> \
--name datasette \
--image <marketplace-image-urn> \
--size Standard_B2ms \
--admin-username azureuser \
--ssh-key-values ~/.ssh/id_ed25519.pub \
--vnet-name <your-vnet> --subnet <your-subnet> \
--public-ip-sku Standard
az vm open-port --resource-group <your-rg> --name datasette --port 80 --priority 1010
Step 3 — Connect to your VM
ssh azureuser@<vm-public-ip>
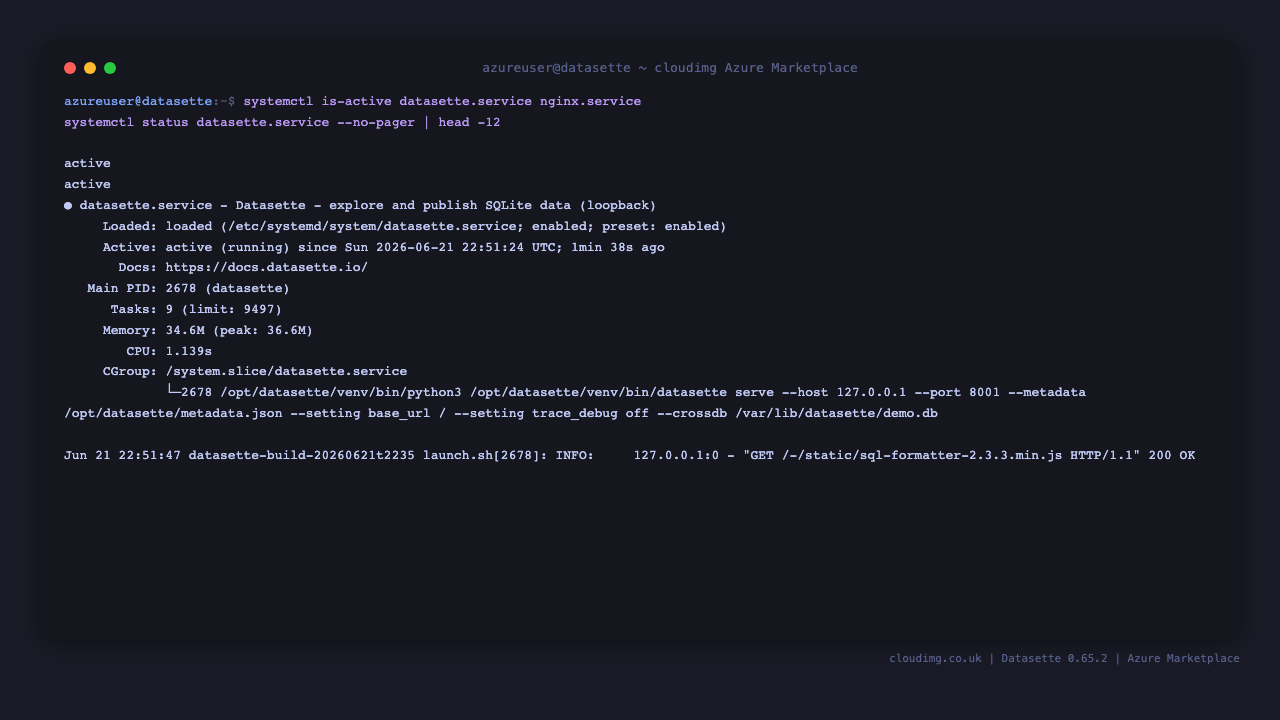
Step 4 — Confirm the services are running
systemctl is-active datasette.service nginx.service
Both services report active. Datasette starts in seconds and immediately serves every *.db file under /var/lib/datasette.
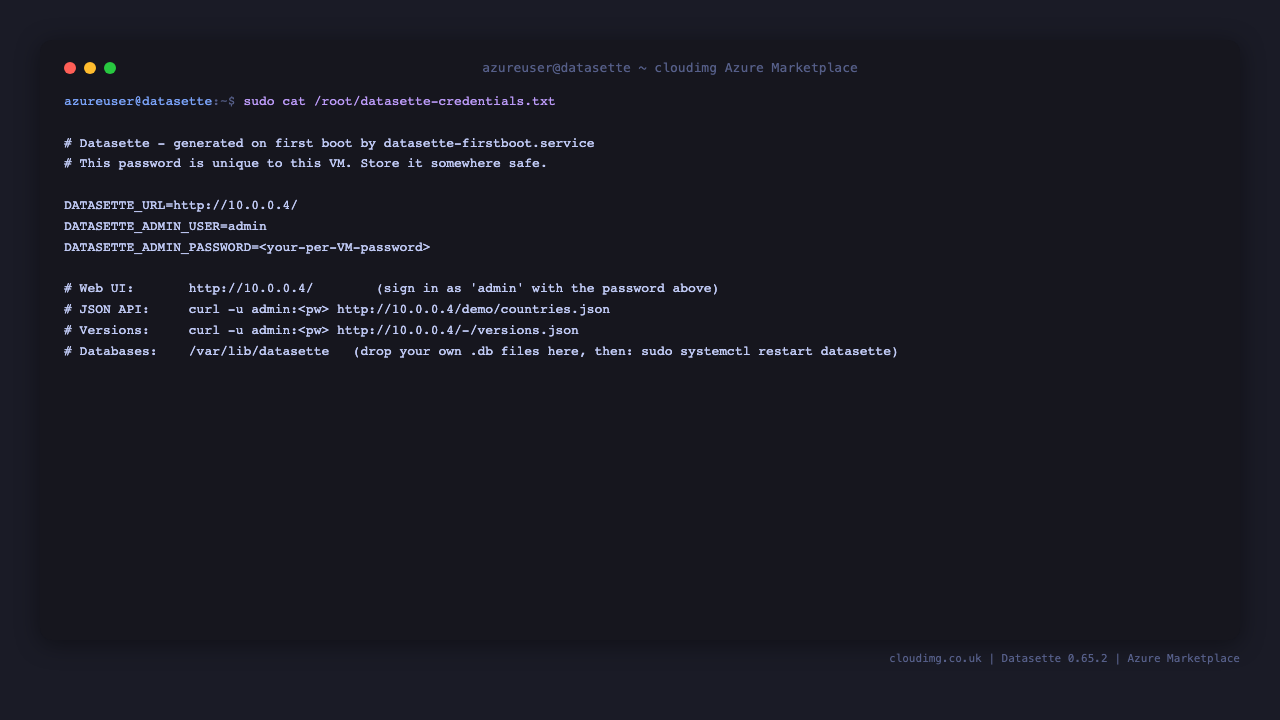
Step 5 — Retrieve your web password
The admin password is generated uniquely on the first boot of your VM and written to a root-only file:
sudo cat /root/datasette-credentials.txt
This file contains DATASETTE_ADMIN_USER (admin) and DATASETTE_ADMIN_PASSWORD, plus the URLs for the web UI and API. Store the password somewhere safe.
Step 6 — Check the health endpoint
nginx serves an unauthenticated health endpoint for load balancers and probes:
curl -s http://localhost/health
It returns ok.
Step 7 — Open the web UI
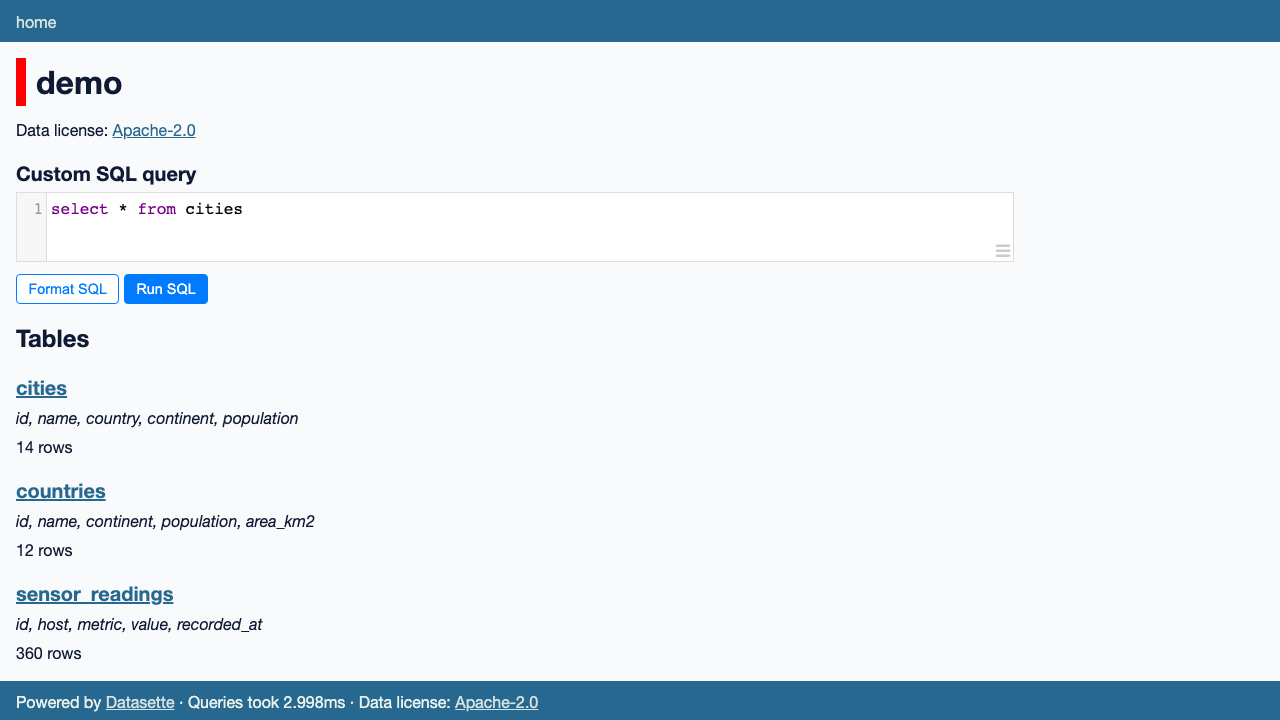
Browse to http://<vm-public-ip>/ and sign in as admin with the password from Step 5. The image ships a demo.db sample database with three tables — countries, cities and sensor_readings — so the UI shows real data out of the box. Click demo to see its tables and row counts:
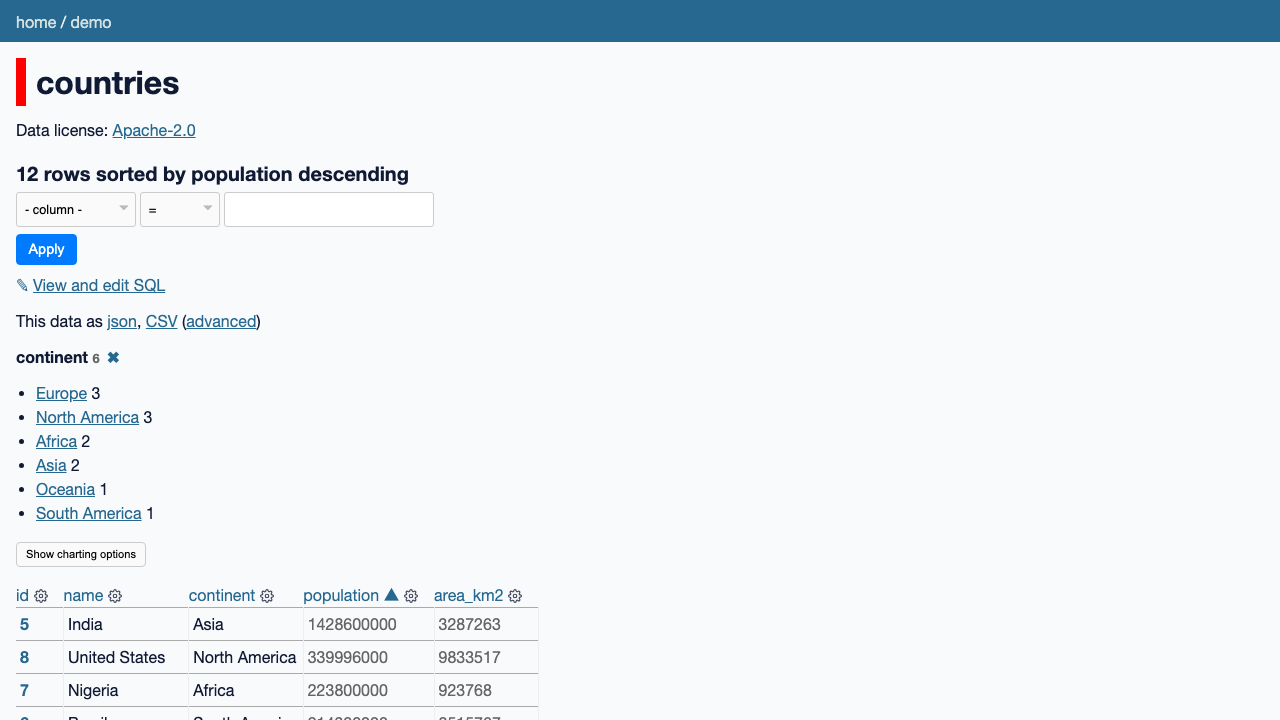
Open the countries table. Datasette's faceted browsing lets you click a column (here continent) to see counts per value and filter instantly, while the column headers sort and the results stay shareable as a URL:
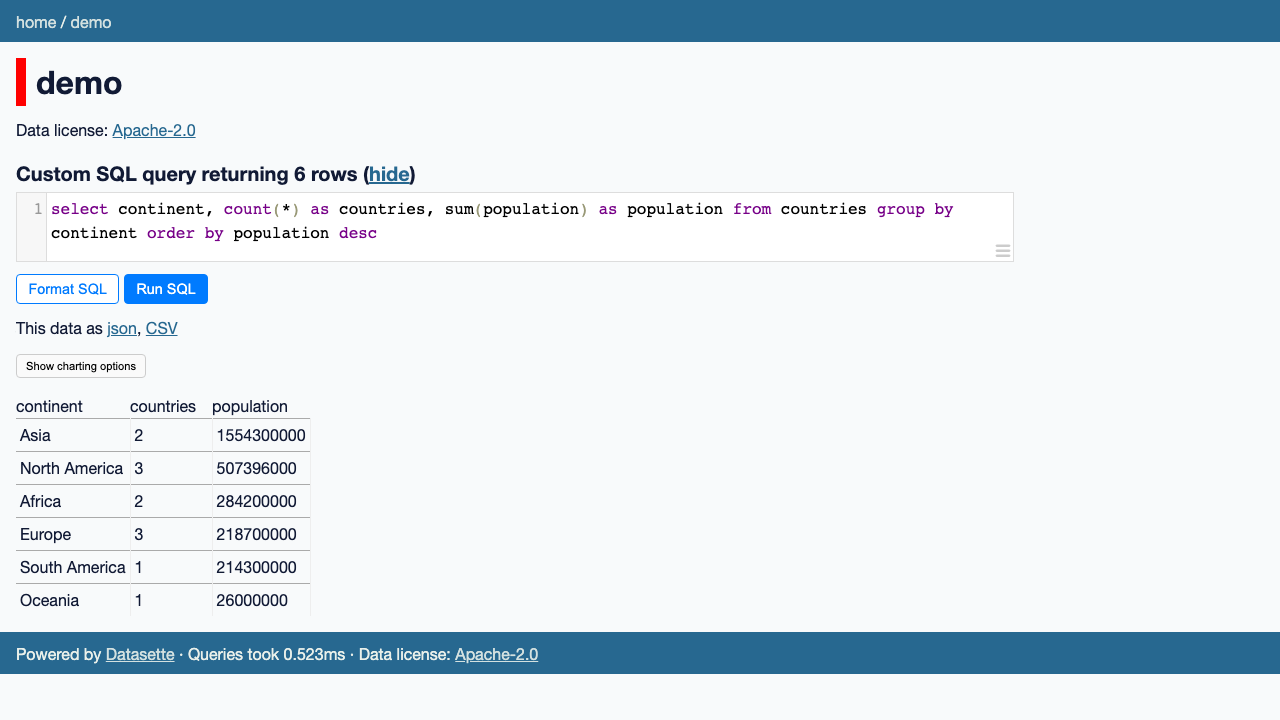
The Custom SQL query box runs any read-only SELECT against the database and returns a result table you can export as JSON or CSV:
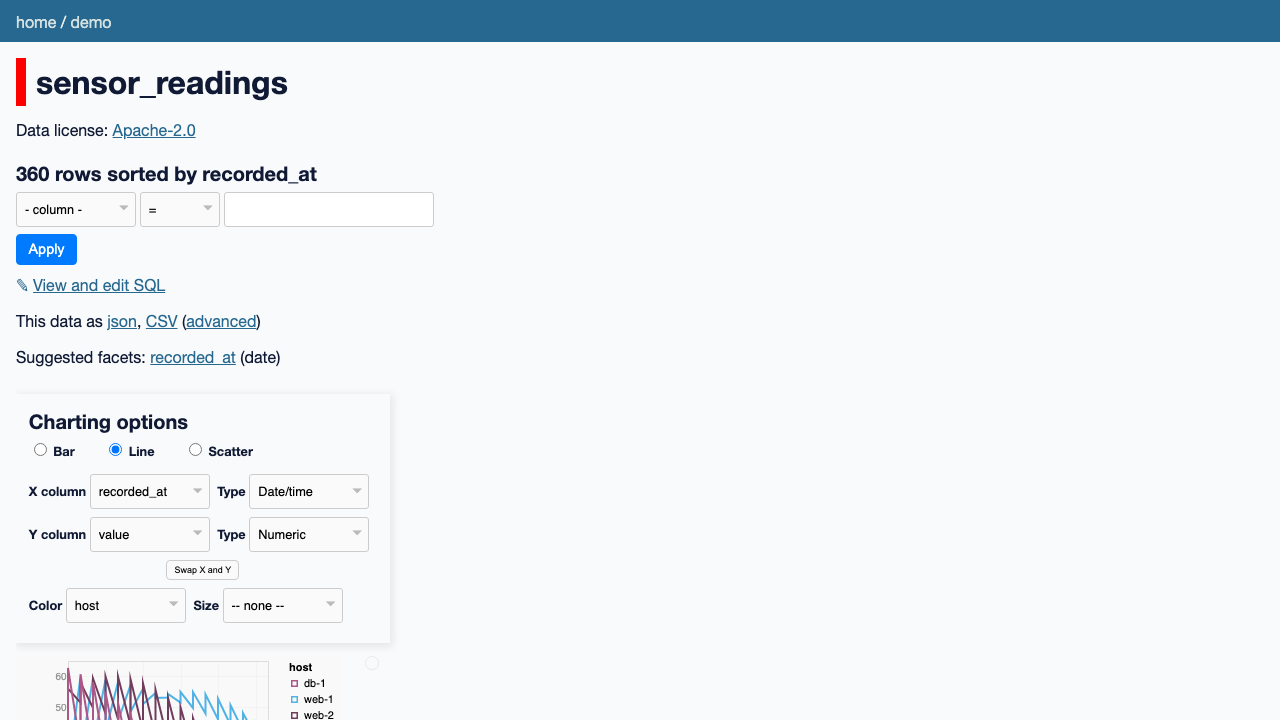
With the bundled datasette-vega plugin, any table or query result can be rendered as a chart. Open sensor_readings, click Show charting options, and plot the time series as a line chart coloured by host:
Step 8 — Query the JSON API
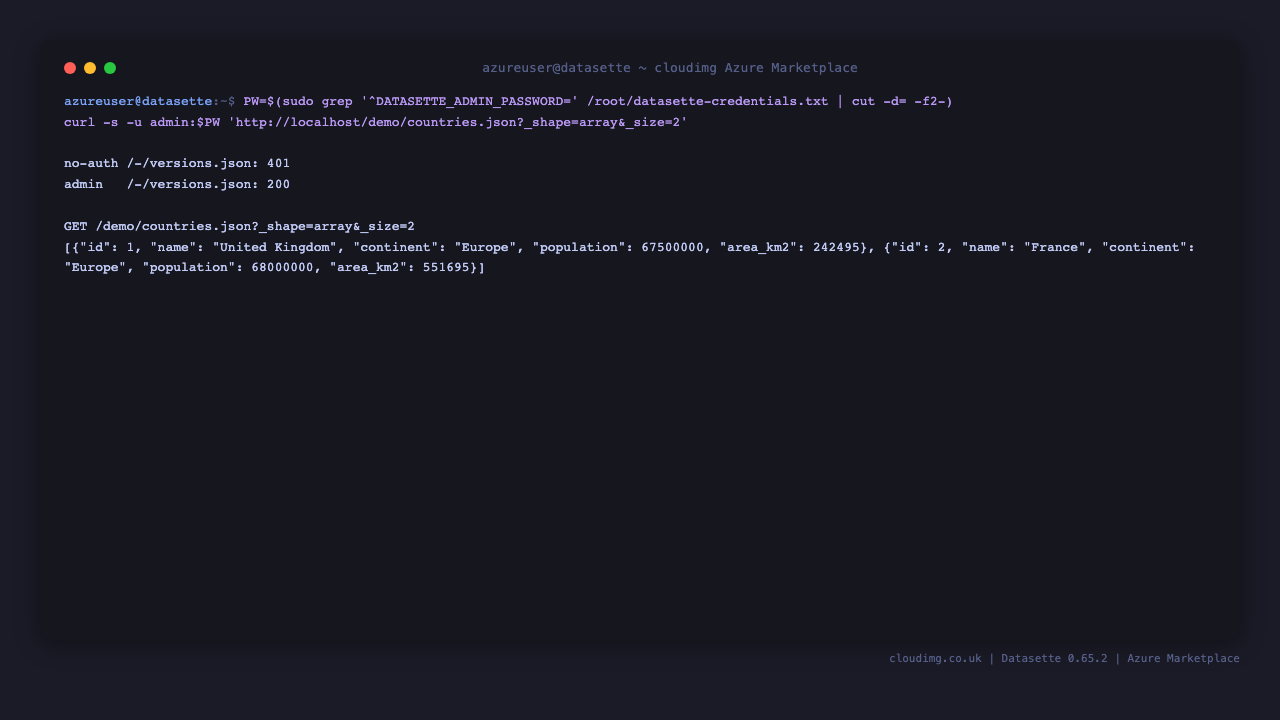
Every page in Datasette has a JSON equivalent — add .json to the URL. The API is behind the same Basic auth. Confirm Datasette is serving and report its version:
curl -s -u admin:<DATASETTE_ADMIN_PASSWORD> http://localhost/-/versions.json; echo
You get a JSON object whose datasette.version field carries the running version (0.65.2). Fetch rows from a table as a JSON array:
curl -s -u admin:<DATASETTE_ADMIN_PASSWORD> 'http://localhost/demo/countries.json?_shape=array&_size=2'; echo
Each object is one row. Use _size to page, _sort/_sort_desc to order, and ?<column>=<value> to filter. The API rejects requests without credentials (401) and returns the rows with them (200):
Step 9 — Run SQL through the API
You can run an arbitrary read-only SELECT through the API by passing it as the sql parameter on the database's JSON endpoint:
curl -s -u admin:<DATASETTE_ADMIN_PASSWORD> 'http://localhost/demo.json?sql=select+count(*)+as+n+from+cities&_shape=array'; echo
This returns [{"n": 14}]. Datasette only permits read-only queries, so the API is safe to expose to analysts behind the auth wall.
Step 10 — Add your own databases
Datasette serves every .db file in /var/lib/datasette. To publish your own data, copy a SQLite database onto the data disk and restart the service. From your workstation:
scp mydata.db azureuser@<vm-public-ip>:/tmp/mydata.db
Then on the VM:
sudo install -o datasette -g datasette -m 0644 /tmp/mydata.db /var/lib/datasette/mydata.db
sudo systemctl restart datasette.service
The new database appears in the web UI and at http://<vm-public-ip>/mydata within a couple of seconds. You can also build a database in place with the sqlite3 CLI (installed on the image) under /var/lib/datasette, or generate one with tools such as sqlite-utils.
Step 11 — Confirm data lives on the dedicated disk
All databases are stored on the dedicated Azure data disk so they survive OS changes and can be resized independently:
findmnt /var/lib/datasette
The mount is backed by a separate Azure data disk captured into the image and re-provisioned on every VM.
Enabling HTTPS
The nginx reverse proxy terminates plain HTTP on port 80. For public exposure, put a certificate in front of it. The simplest path is to add a DNS name for the VM and use the companion cloudimg nginx-ssl-certbot image as a TLS reverse proxy, or install certbot and extend the existing nginx site (/etc/nginx/sites-available/cloudimg-datasette) with a listen 443 ssl; server block and your certificate paths. Keep Datasette itself bound to loopback so the only public surface is the authenticated, TLS-terminated proxy.
Maintenance
- Configuration: the service launches Datasette via
/opt/datasette/launch.sh, which serves every*.dbunder/var/lib/datasettewith the metadata in/opt/datasette/metadata.json. Edit those andsudo systemctl restart datasetteto apply changes. - Changing the web password: rewrite the htpasswd entry with
sudo htpasswd -b /etc/nginx/.htpasswd admin '<new-password>'andsudo systemctl reload nginx. - Backups: snapshot the
/var/lib/datasettedata disk, or copy individual.dbfiles to Azure Blob Storage. - Upgrades: upgrade in the virtualenv with
sudo /opt/datasette/venv/bin/pip install -U datasetteand restart the service. - Security patches: unattended-upgrades remains enabled so the OS continues to receive security updates automatically.
Support
cloudimg provides 24/7 expert support for this image. Contact support@cloudimg.co.uk.
Datasette is an open-source project created by Simon Willison and distributed under the Apache License 2.0. This image is produced by cloudimg and is not affiliated with or endorsed by the Datasette project.