LocalAI on Ubuntu 24.04 on Azure User Guide
Overview
LocalAI is a free, open source, self hosted drop in replacement for the OpenAI API. It exposes the same OpenAI compatible REST API for chat completions, completions and embeddings, but runs entirely on your own infrastructure with no external API calls and no GPU required, using the llama.cpp GGUF backend for inference on commodity CPU. The cloudimg image installs LocalAI 4.4.3 as the single local-ai binary at /usr/local/bin/local-ai, runs it as a dedicated localai system user bound to loopback behind an nginx reverse proxy on TCP 80 with HTTP Basic auth, stores all models on a dedicated Azure data disk, pre pulls a small instruct model so the API and the web UI work the moment the VM boots, and generates a unique web password on the first boot of every VM. Backed by 24/7 cloudimg support.
What is included:
- LocalAI 4.4.3 at
/usr/local/bin/local-ai - The built in web UI and the OpenAI compatible REST API (
/v1/chat/completions,/v1/embeddings,/v1/modelsand more), fronted by nginx on:80 - nginx HTTP Basic auth (LocalAI has no built in authentication) with a per VM password in a root only file
- A small CPU friendly instruct model (
smollm2-135m-instruct) pre pulled so the chat API and the web UI work out of the box with no internet access - The CPU llama.cpp inference backend pre pulled, so inference runs offline with no GPU
- A dedicated Azure data disk at
/var/lib/localaiholding the models directory, separate from the OS disk and re provisioned with every VM localai.service+nginx.serviceas systemd units, enabled and active- 24/7 cloudimg support
Prerequisites
An active Azure subscription, an SSH key pair, and a VNet + subnet in the target region. Standard_B4ms (4 vCPU / 16 GiB RAM) is a good starting point for CPU inference; scale up for larger models or higher throughput. NSG inbound: allow 22/tcp from your management network and 80/tcp for the web UI and API (front with TLS for public exposure, see Enabling HTTPS).
Step 1 - Deploy from the Azure Marketplace
Sign in to the Azure Portal, choose Create a resource, search the Marketplace for LocalAI by cloudimg, and select Create. On Basics pick your subscription, resource group, region and size; under Administrator account choose SSH public key and paste your key; under Inbound port rules allow SSH (22) and HTTP (80). Review the dedicated data disk on the Disks tab, then Review + create then Create.
Step 2 - Deploy from the Azure CLI
az vm create \
--resource-group <your-rg> \
--name localai \
--image <marketplace-image-urn> \
--size Standard_B4ms \
--admin-username azureuser \
--ssh-key-values ~/.ssh/id_ed25519.pub \
--vnet-name <your-vnet> --subnet <your-subnet> \
--public-ip-sku Standard
az vm open-port --resource-group <your-rg> --name localai --port 80 --priority 1010
Step 3 - Connect to your VM
ssh azureuser@<vm-public-ip>
Step 4 - Confirm the services are running
systemctl is-active localai.service nginx.service
Both services report active. LocalAI loads the pre pulled model on first boot and is ready to serve the OpenAI compatible API immediately.
Step 5 - Retrieve your web password
The admin password is generated uniquely on the first boot of your VM and written to a root only file:
sudo cat /root/localai-credentials.txt
This file contains localai.user (admin) and localai.password, plus the URL for the web UI. Store the password somewhere safe.
Step 6 - Check the health endpoint
nginx serves an unauthenticated health endpoint for load balancers and probes:
curl -s http://localhost/health
It returns ok.
Step 7 - Open the web UI
Browse to http://<vm-public-ip>/ and sign in as admin with the password from Step 5. The home page shows system status, the pre pulled model loaded and ready, and a chat box. Use the left nav to reach Chat, Install Models, Studio and Talk.
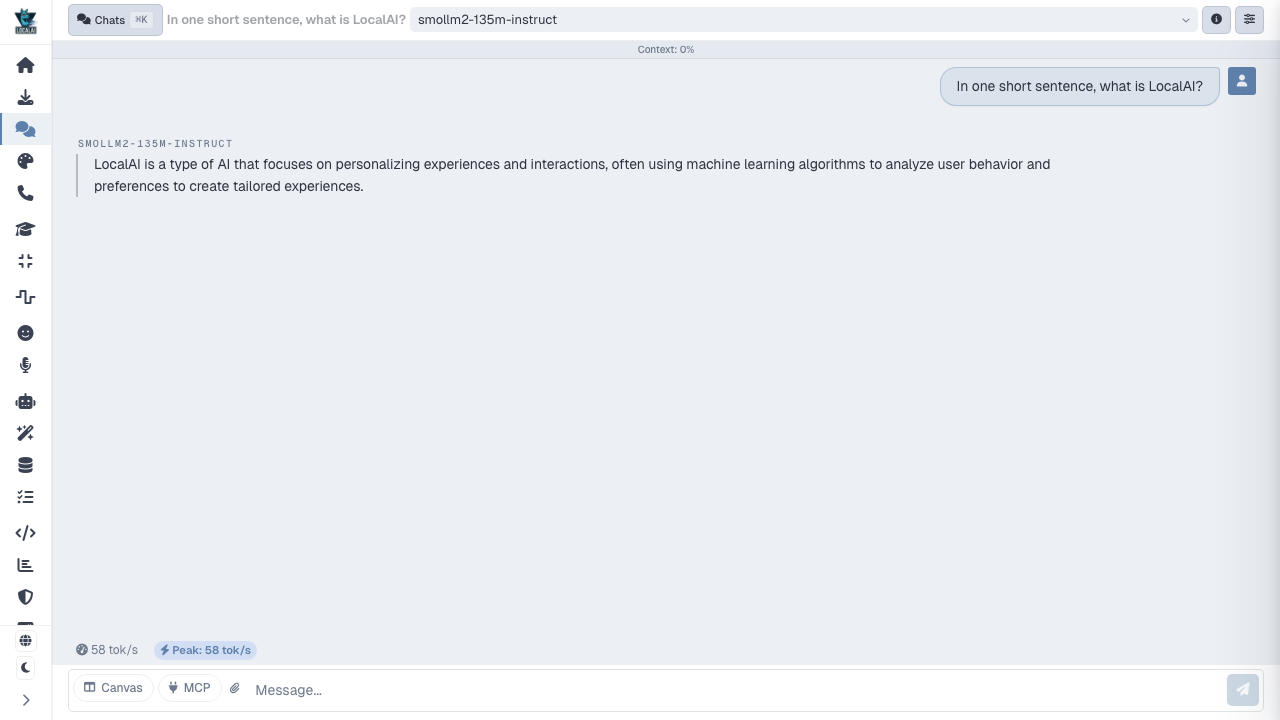
Open Chat in the left nav, pick the smollm2-135m-instruct model, type a message and send it. The model runs on the VM CPU and streams its reply:
Step 8 - Call the OpenAI compatible API
The OpenAI compatible REST API is served on the same port 80 behind the same Basic auth. List the available models:
curl -s -u admin:<LOCALAI_ADMIN_PASSWORD> http://localhost/v1/models | jq .
You get a JSON response whose data array includes the pre pulled smollm2-135m-instruct model. A request without credentials returns 401.
Run a chat completion against the pre pulled model:
curl -s -u admin:<LOCALAI_ADMIN_PASSWORD> http://localhost/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{"model":"smollm2-135m-instruct","messages":[{"role":"user","content":"In one sentence, what is Azure?"}],"max_tokens":64,"temperature":0.2}' | jq -r '.choices[0].message.content'
The response is generated by the model running locally on the VM CPU. Point any OpenAI client library or tool at http://<vm-public-ip>/v1 with HTTP Basic credentials and change only the base URL to run existing applications against models on your own hardware.
Step 9 - Generate embeddings
LocalAI also serves the OpenAI compatible embeddings endpoint. Embedding models are installed from the gallery (see Step 10); once an embedding model such as bert-embeddings is installed, request a vector with:
curl -s -u admin:<LOCALAI_ADMIN_PASSWORD> http://localhost/v1/embeddings \
-H 'Content-Type: application/json' \
-d '{"model":"bert-embeddings","input":"The quick brown fox"}' | jq '.data[0].embedding | length'
The response carries the embedding vector under data[0].embedding.
Step 10 - Install more models from the gallery
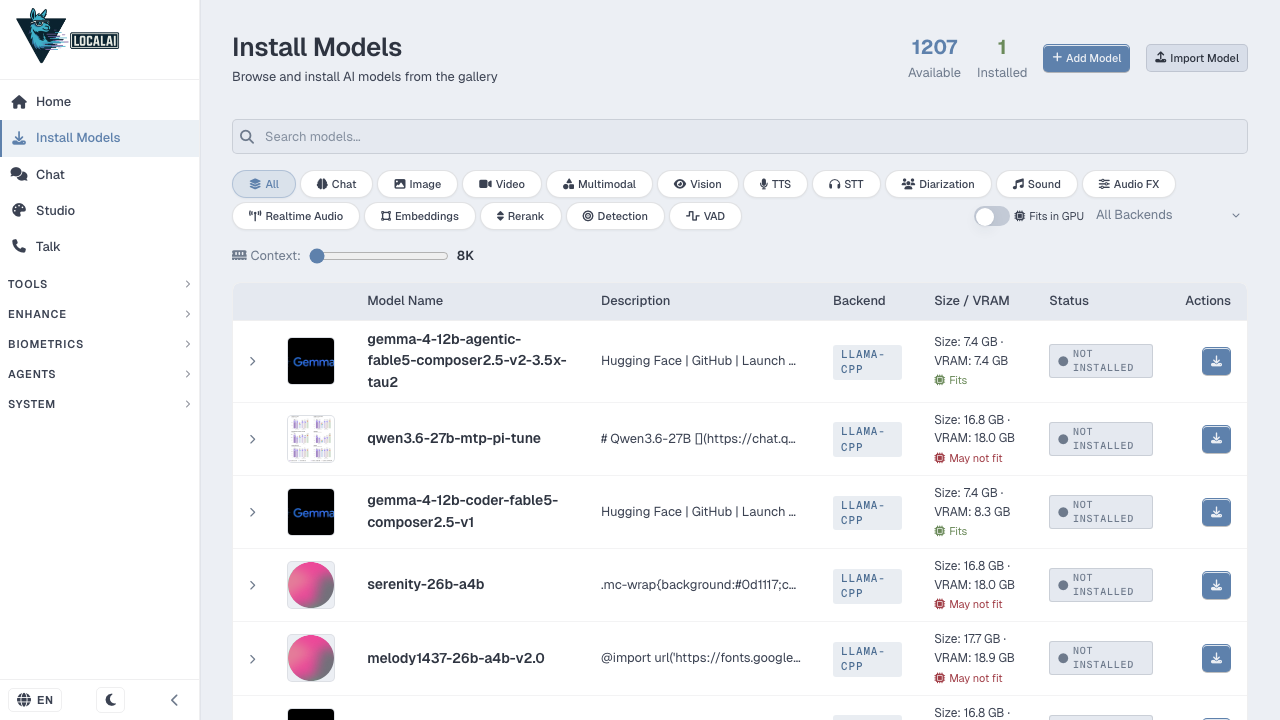
The image ships one small model so the API works out of the box. LocalAI's gallery offers hundreds more. In the web UI, open Install Models in the left nav, search the gallery, and click install on any model:
You can also install a model from the command line with the model apply API:
curl -s -u admin:<LOCALAI_ADMIN_PASSWORD> http://localhost/models/apply \
-H 'Content-Type: application/json' \
-d '{"id":"localai@qwen2.5-0.5b-instruct"}'
Installed models are downloaded into the models directory on the dedicated data disk and appear in /v1/models once ready. Larger models need more RAM and CPU, so choose a VM size to match.
Step 11 - Confirm models live on the dedicated disk
All models are stored on the dedicated Azure data disk so they survive OS changes and can be resized independently:
findmnt /var/lib/localai
The mount is backed by a separate Azure data disk captured into the image and re provisioned on every VM. The pre pulled model and the CPU inference backend live under /var/lib/localai/models and /var/lib/localai/backends.
Enabling HTTPS
The nginx reverse proxy terminates plain HTTP on port 80. For public exposure, put a certificate in front of it. The simplest path is to add a DNS name for the VM and use the companion cloudimg nginx-ssl-certbot image as a TLS reverse proxy, or install certbot and extend the existing nginx site with a listen 443 ssl; server block and your certificate paths. Keep LocalAI itself bound to loopback so the only public surface is the authenticated, TLS terminated proxy.
Maintenance
- Configuration: the runtime settings (models path, backends path, loopback address, context size, threads) are set in
/etc/localai/localai.env. Edit it andsudo systemctl restart localaito apply changes. - Backups: snapshot the
/var/lib/localaidata disk to preserve your installed models. - Upgrades: replace
/usr/local/bin/local-aiwith a newer release and restart the service. - Security patches: unattended-upgrades remains enabled so the OS continues to receive security updates automatically.
Support
cloudimg provides 24/7 expert support for this image. Contact support@cloudimg.co.uk.
LocalAI is a trademark of its respective owner. This image is produced by cloudimg and is not affiliated with or endorsed by the LocalAI project. LocalAI is distributed under the MIT License.