Paperless-ngx on AWS User Guide
Overview
This image runs Paperless-ngx bare metal behind nginx. The granian application server serves the bundled Angular frontend on the loopback interface, a Celery worker and a Celery beat scheduler run the background task pipeline, and a consumer process watches an input folder for new documents. PostgreSQL provides the database and Redis provides the Celery task broker, all on the same instance and bound to the loopback interface only. The optical character recognition pipeline is built on tesseract, Ghostscript and OCRmyPDF, so scanned PDFs and images are made fully text searchable on import.
Paperless administrator and PostgreSQL credentials are generated on the first boot of every deployed instance. Two instances launched from the same Amazon Machine Image never share passwords. A fresh Django secret key is generated at the same time. The initial administrator password and the PostgreSQL password are written to /root/paperless-ngx-credentials.txt with mode 0600 so that only the root user can read them. No documents and no shared credentials ship in the image.
The Paperless application code, the document media archive, the data directory, the consume folder and the search index all live under /opt/paperless on a dedicated EBS volume separate from the operating system disk. The PostgreSQL data directory sits on its own EBS volume at /var/lib/postgresql. Each tier can be resized independently of the others.
Prerequisites
Before you deploy this image you need:
- An Amazon Web Services account where you can launch EC2 instances
- IAM permissions to launch instances, create security groups, and subscribe to AWS Marketplace products
- An EC2 key pair in the target Region for SSH access to the instance
- A VPC and subnet in the target Region, with a security group allowing inbound port 22 from your management network and inbound ports 80 and 443 from the networks your users will reach Paperless on
- The AWS CLI (version 2) installed locally if you plan to deploy from the command line
Step 1: Launch the Instance from the AWS Marketplace
Sign in to the AWS Management Console, open the EC2 service, and select Launch instance. Under Application and OS Images choose AWS Marketplace AMIs and search for Paperless-ngx. Select the cloudimg listing and choose Select, then Continue on the subscription summary.
Pick an instance type of m5.large or larger — the OCR pipeline is processor and memory heavy, and document throughput benefits from both. Choose your EC2 key pair under Key pair (login). Under Network settings select your VPC and subnet, and either create or select a security group that allows inbound port 22 from your management network and inbound ports 80 and 443 from the networks your users use. Leave the root volume at the default size or larger.
Select Launch instance. First boot initialisation takes approximately one minute after the instance state becomes Running and the status checks pass.
Step 2: Launch the Instance from the AWS CLI
The following block launches an instance from the cloudimg Paperless-ngx Marketplace AMI into an existing subnet and security group. Replace <ami-id> with the AMI ID shown on the Marketplace listing, <key-name> with your EC2 key pair name, <subnet-id> with your subnet ID, and <security-group-id> with a security group that opens ports 22, 80, and 443 as described above.
aws ec2 run-instances \
--image-id <ami-id> \
--instance-type m5.large \
--key-name <key-name> \
--subnet-id <subnet-id> \
--security-group-ids <security-group-id> \
--block-device-mappings '[{"DeviceName":"/dev/sda1","Ebs":{"VolumeSize":20,"VolumeType":"gp3"}}]' \
--tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=paperless-01}]'
The command prints a JSON document on success. Note the instance ID, then retrieve its public address once it is running with aws ec2 describe-instances --instance-ids <instance-id> --query "Reservations[].Instances[].PublicIpAddress" --output text.
Step 3: Connect and Retrieve Initial Credentials
Connect over SSH with the key pair you selected and the public IP address from step 2. The SSH login user depends on the operating system of the AMI variant you launched:
| AMI variant | SSH login user |
|---|---|
| Paperless-ngx 2.20 on Ubuntu 24.04 | ubuntu |
ssh -i <key.pem> ubuntu@<public-ip>
The per instance administrator and PostgreSQL passwords are written to a root only file. Read it with sudo:
sudo cat /root/paperless-ngx-credentials.txt
The file lists the Paperless administrator username (admin) and password, the database name, user and password, and the URL to reach the web interface. Keep these somewhere safe.
Step 4: The Trusted Host Model
Django, the web framework Paperless is built on, only serves requests whose Host header it trusts, and only accepts form posts from trusted origins. On first boot the instance adds its own public and private addresses to PAPERLESS_URL and PAPERLESS_CSRF_TRUSTED_ORIGINS in /opt/paperless/paperless.conf, so the web interface is reachable immediately on the instance's launch address. If you put Paperless behind a custom domain or a load balancer, add that hostname too and restart the webserver:
sudo sed -i 's|^PAPERLESS_URL=.*|PAPERLESS_URL=https://paperless.your-domain.example|' /opt/paperless/paperless.conf
sudo systemctl restart paperless-webserver
Step 5: First Login to the Paperless Web Interface
Open a web browser and navigate to http://<public-ip>/. Paperless presents its sign-in page. Enter the administrator username admin and the administrator password from /root/paperless-ngx-credentials.txt, then select Sign in.
After signing in you reach the Dashboard, which shows saved views and statistics, and the Documents list, which is the heart of the platform — every document you import is OCRed, tagged and full text searchable here.
Step 6: Change the Administrator Password
For a production deployment rotate the administrator password that was generated on first boot. Select the gear or your user menu, open My Profile, and change the password there.
You can also reset it from the command line. The Paperless manage.py changepassword admin command prompts you for the new password interactively; run it from your SSH session and type the new password when asked. The management command is invoked as the paperless user with the configuration path set, like every other admin command shown in step 10.
Step 7: Import and OCR Your First Document
Paperless imports documents by watching a consume directory. Anything you drop into /opt/paperless/consume is picked up by the consumer, OCRed, indexed and archived automatically. Copy a PDF or scanned image there with sudo cp <your-file>.pdf /opt/paperless/consume/ and make the paperless user the owner with sudo chown paperless:paperless /opt/paperless/consume/<your-file>.pdf.
Within a few seconds the consumer hands the file to a Celery worker, which runs OCR and indexing. The file then disappears from the consume directory and appears in the Documents list in the web interface, with its extracted text searchable. You can watch the pipeline work with journalctl -u paperless-consumer -u paperless-task-queue -f (press Ctrl-C to stop following), or check the recent log without following:
sudo journalctl -u paperless-consumer -u paperless-task-queue --no-pager -n 20
Scanners and network shares can write straight into /opt/paperless/consume over NFS, SMB or scp, which is the usual way to feed a paperless office.
Step 8: The REST API
Paperless exposes a full REST API under /api/. It requires authentication; the sign-in page itself is open. You can verify both with curl — the unauthenticated request is rejected and the authenticated one succeeds:
# The sign-in page is served without authentication
curl -s -o /dev/null -w '%{http_code}\n' http://127.0.0.1/accounts/login/
# Without credentials the API is rejected
curl -s -o /dev/null -w '%{http_code}\n' http://127.0.0.1/api/documents/
# With the admin credentials it returns 200
curl -s -o /dev/null -w '%{http_code}\n' -u admin:<PAPERLESS_ADMIN_PASSWORD> http://127.0.0.1/api/documents/
You can also issue a long lived API token from My Profile in the web interface and pass it as Authorization: Token <token> for automation and integrations.
Step 9: Tags, Correspondents and Document Types
Paperless organises documents with tags, correspondents (who a document is from), document types (invoice, contract, payslip) and storage paths. Create these from the left hand menu, then build matching rules so Paperless applies them automatically on import — for example tagging anything from a given correspondent, or matching documents whose OCR text contains a keyword. Saved views on the dashboard let you pin the searches you run most.
Step 10: Services and Operations
The image runs seven systemd units. Check their state at any time:
systemctl status postgresql redis-server nginx \
paperless-webserver paperless-task-queue paperless-scheduler paperless-consumer
The paperless-webserver unit runs the granian application server on 127.0.0.1:8000; nginx reverse proxies port 80 to it. The paperless-task-queue and paperless-scheduler units are the Celery worker and beat scheduler; paperless-consumer watches the consume directory. Run Paperless management commands as the paperless user:
sudo -u paperless PAPERLESS_CONFIGURATION_PATH=/opt/paperless/paperless.conf \
/opt/paperless/.venv/bin/python /opt/paperless/src/manage.py <command>
Step 11: Enable HTTPS with Let's Encrypt
For any production deployment serve the site over HTTPS so session cookies and document transfers cannot be intercepted. The image ships with nginx, which certbot can configure automatically.
The following assumes you have a DNS record pointing your fully qualified domain name at the instance's public IP address, and that you have added that domain to PAPERLESS_URL and PAPERLESS_CSRF_TRUSTED_ORIGINS (step 4).
sudo apt-get update && sudo apt-get install -y certbot python3-certbot-nginx
sudo certbot --nginx -d paperless.your-domain.example \
--non-interactive --agree-tos -m you@your-domain.example \
--redirect
After certbot finishes, point Paperless at the HTTPS URL so it generates correct links and trusts the origin:
sudo sed -i 's|^PAPERLESS_URL=.*|PAPERLESS_URL=https://paperless.your-domain.example|' /opt/paperless/paperless.conf
sudo systemctl restart paperless-webserver
Step 12: Backups and Maintenance
Paperless has two things that must be backed up together: the PostgreSQL database and the document store under /opt/paperless/media. The cleanest backup is Paperless's own document exporter, which writes a self contained, importable archive:
sudo -u paperless PAPERLESS_CONFIGURATION_PATH=/opt/paperless/paperless.conf \
/opt/paperless/.venv/bin/python /opt/paperless/src/manage.py document_exporter /var/backups/paperless
Ship the export directory to an Amazon S3 bucket or another object store. Because the data and database tiers are on their own EBS volumes, you can also take coordinated EBS snapshots. The scheduler runs Paperless's periodic tasks, such as email checking and index optimisation, automatically.
For kernel and package updates, Ubuntu's unattended-upgrades is enabled by default, so security patches apply automatically. To update Paperless itself, follow the upgrade workflow in the official documentation at https://docs.paperless-ngx.com/.
Step 13: Scaling Beyond a Single Instance
For larger deployments decouple Paperless from the single instance pattern:
- Move PostgreSQL to Amazon RDS for PostgreSQL and update the database host in
/opt/paperless/paperless.conf - Move the document store to Amazon S3 using Paperless's object storage support, or to Amazon EFS
- Move Redis to Amazon ElastiCache for Redis and point
PAPERLESS_REDISat the cluster endpoint - Put the web tier behind an Application Load Balancer, add the load balancer hostname to the trusted origins, and run the Celery workers on dedicated instances
- Serve static assets through Amazon CloudFront
Each of these is documented in the official Paperless-ngx documentation at https://docs.paperless-ngx.com/.
Screenshots
The Paperless-ngx sign-in page, served on first boot with a per-instance administrator password and no manual setup.
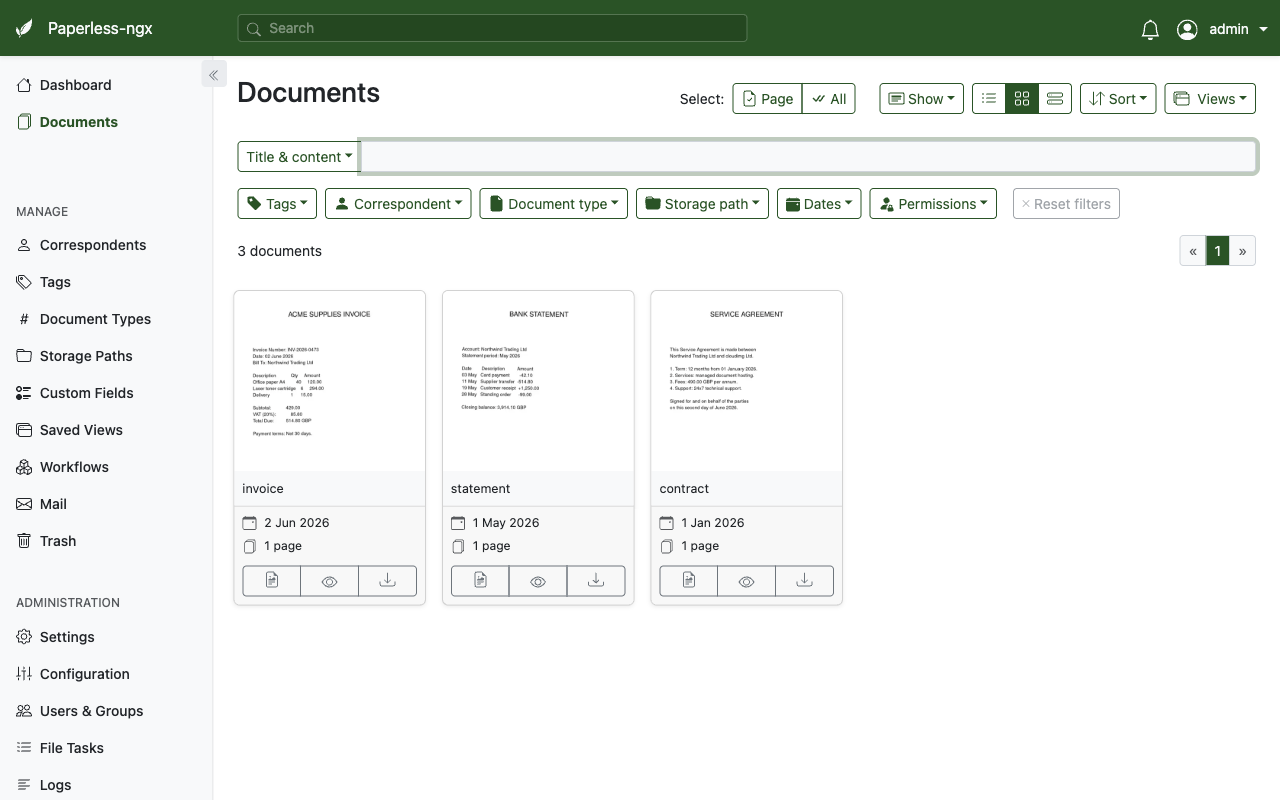
The Paperless-ngx documents view after signing in as the administrator, the searchable document archive.
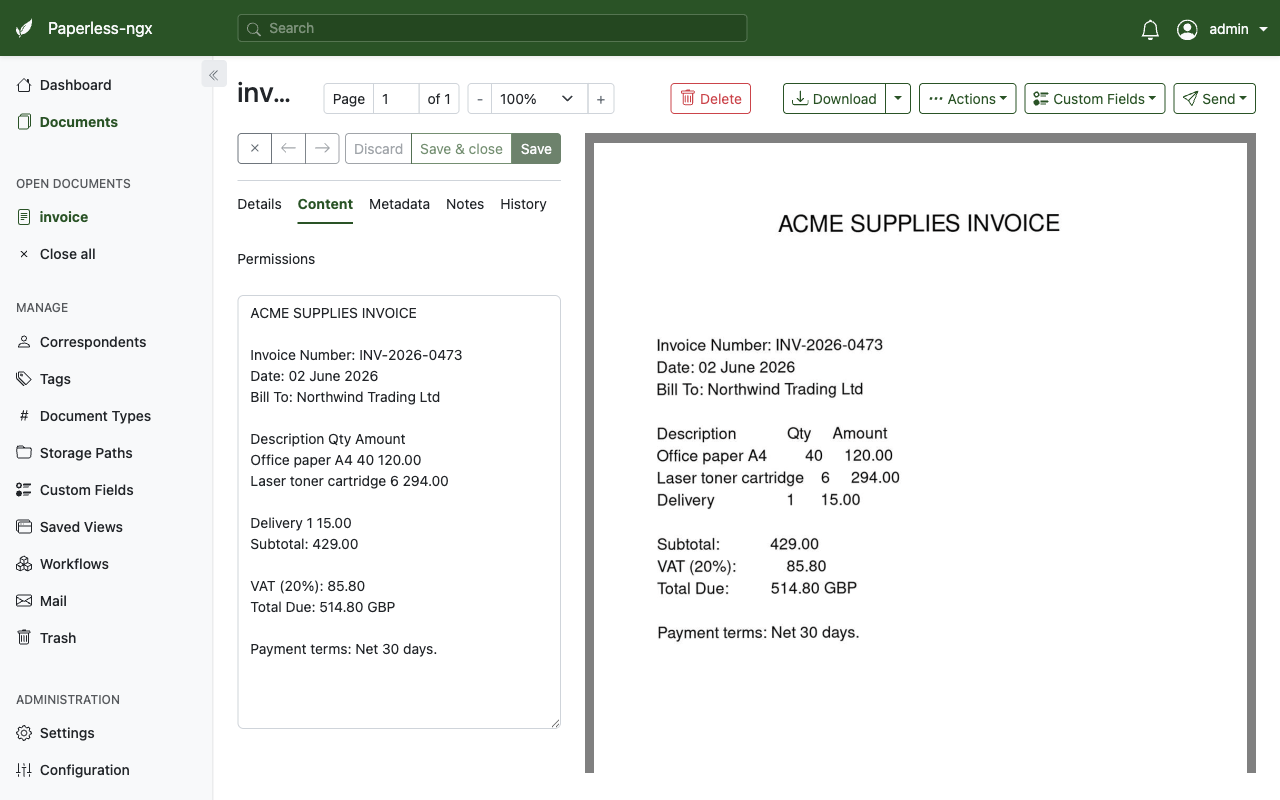
A document detail view showing the rendered preview alongside the OCR extracted, full text searchable content.
Support
cloudimg provides 24/7/365 expert technical support for this image. Guaranteed response within 24 hours, one hour average for critical issues. Contact support@cloudimg.co.uk.